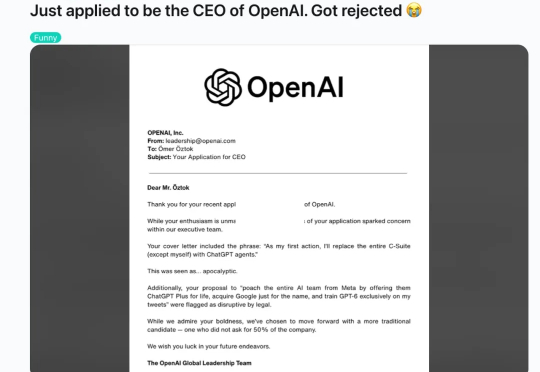
「我申请当 OpenAI CEO ,收到了一封拒绝信」
「我申请当 OpenAI CEO ,收到了一封拒绝信」论搞事情,网友们从来不让人失望。 这不,最近海外又出了个营销大整活,网友 Ömer Öztok 声称自己给 OpenAI 投了份申请担任 CEO 的简历。
来自主题: AI资讯
7963 点击 2025-09-03 11:58
 搜索
搜索
论搞事情,网友们从来不让人失望。 这不,最近海外又出了个营销大整活,网友 Ömer Öztok 声称自己给 OpenAI 投了份申请担任 CEO 的简历。

一群AI玩狼人杀,GPT-5断崖式领先,胜率达到了惊人的96.7%。 OpenAI的总裁格雷格·布罗克曼转发了这样的一个基准测试:让7个强大的LLMs,包括开源和闭源,玩了210场完整的狼人杀。

硅谷炸锅了!xAI创始工程师卖掉700万美元股票后,涉嫌窃取Grok核心代码库「叛逃」OpenAI,马斯克怒发推文「他下载了整个xAI代码库」。这场价值数十亿美元的叛逃案,已在加州法院开打。恩怨升级,马斯克 vs OpenAI,谁将笑到最后?
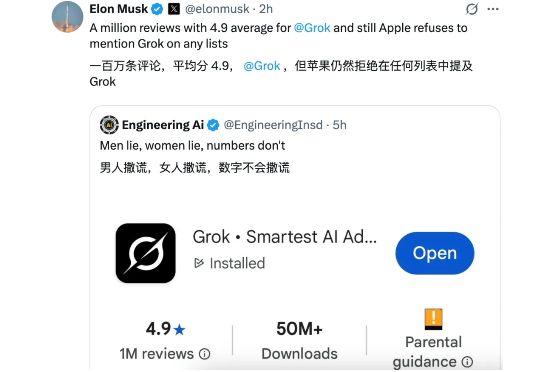
当地时间周一,马斯克向 OpenAI 和苹果「开炮」了! 据多家外媒报道,马斯克旗下 xAI 一纸讼书,控告它们通过 ChatGPT 和苹果 App Store 进行非法垄断。

近日,据外媒消息,Meta 在本周早些时候重组了其人工智能部门后,已冻结招聘。这一举动与 Meta 此前报道的为顶尖人才提供高达 10 亿美元薪酬的计划截然不同,此前数周,该公司已从竞争对手那里挖走了 50 多名人工智能研究人员和工程师,其中包括来自 OpenAI 的 20 名研究人员和工程师,至少 13 名来自谷歌、3 名来自苹果、3 名来自 xAI 以及 2 名来自 Anthropic。
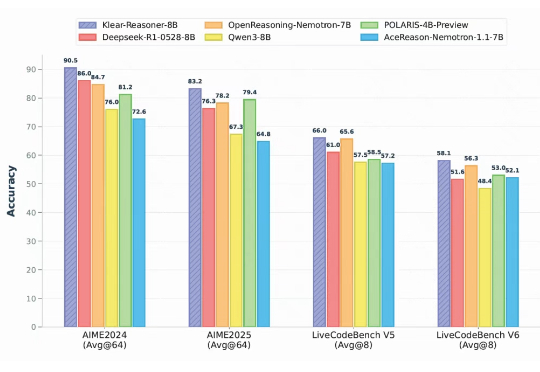
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
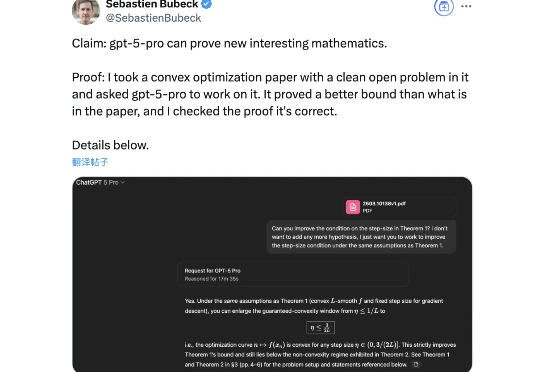
AI已经能够自主思考并证明新的数学规律了? OpenAI研究人员表示,自己喂给GPT-5 Pro一篇论文,结果模型读完之后得到了新的结论。

4 个月前,OpenAI 的 o3 模型凭借视觉推理能力模块和智能的进化,在 AI 创投圈子引起新一轮的震撼与海啸,解锁了一大批新的「套壳」创业机会。正如我们在《谢谢 OpenAI,谢谢 o3,新的「套壳」创业机会来了 | 附 12 个潜力方向》一文中预测的那样,VLM 确实带来了新的创业机会。

进入 2025 年,GUI Agent 赛道热度逐渐抬升 —— OpenAI 推出 Operator 并发布了 ChatGPT Agent,字节则发布了 UI-TARS-1.5 定位 GUI 开源方案。但大多数产品依然依赖本地执行,难以 24h 稳定运行。
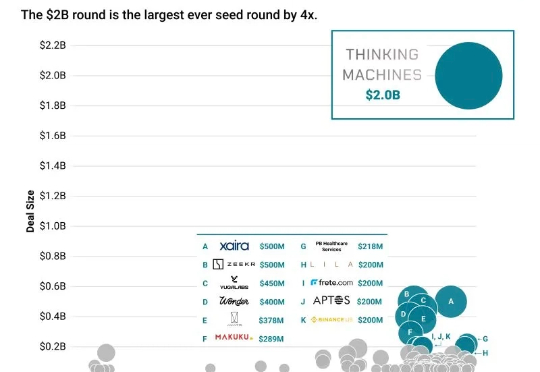
硅谷各个模型公司在这个季度,开始分化到各个领域,除了 Google Gemini 和 OpenAI 还在做通用的模型;Anthropic 分化到 Coding、Agentic 的模型能力;Mira 的 Thinking Machines Lab 分化到多模态和下一代交互。